
Related questions
Concept explainers
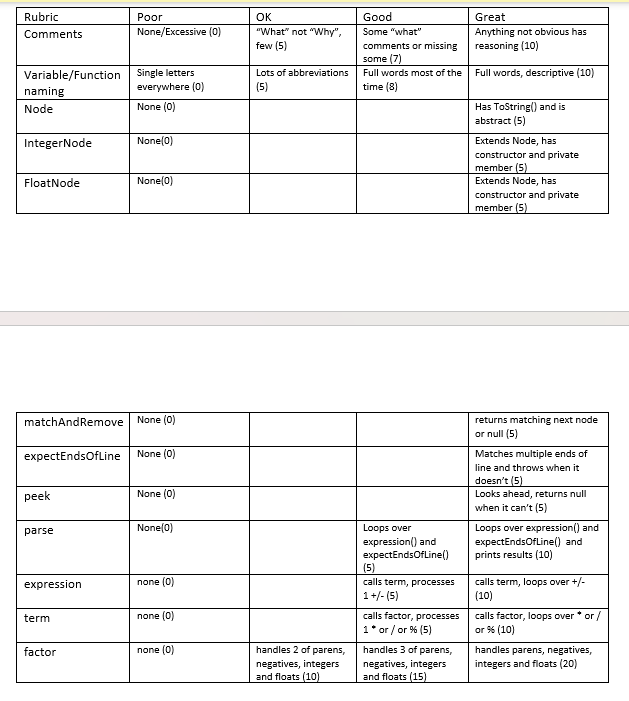
Parser - setup
Make sure to make a Parser class (does not derive from anything). It must have a constructor that accepts your collection of Tokens. We will be treating the collection of tokens as a queue - taking off the front. It isn't necessary to use a Java Queue, but you may.
We will add three helper functions to parser. These should be private:
matchAndRemove - accepts a token type. Looks at the next token in the collection:
If the passed in token type matches the next token's type, remove that token and return it.
If the passed in token type DOES NOT match the next token's type (or there are no more tokens) return null.
expectEndsOfLine - uses matchAndRemove to match and discard one or more ENDOFLINE tokens. Throw a SyntaxErrorException if no ENDOFLINE was found.
peek - accepts an integer and looks ahead that many tokens and returns that token. Returns null if there aren't enough tokens to fulfill the request.
Parser - parse
Make sure to make a public parse method. There are no parameters, and it returns Node. This will be called from main once lexing is complete. For now, we are going to only parse a subset of Shank V2 - mathematical expressions. Parse should call expression() then expectEndOfLine() in a loop until either returns null. Don't worry about storing the return node but you should print it out (using ToString()) for testing.
Below is the parser file. There are errors in the parser.java code. Please fix those errors in the parser.java and make sure the parser works correctly. Attached is the rubric.
package mypack;
import java.util.List;
import mypack.Token.TokenType;
public class Parser {
private List<Token> tokens;
private int currentTokenIndex;
public Parser(List<Token> tokens) {
this.tokens = tokens;
this.currentTokenIndex = 0;
}
public Node parse() throws SyntaxErrorException {
Node result = null;
while (peek() != null) {
Node expr = expression();
expectEndOfLine();
System.out.println(expr.toString());
}
return result;
}
private Node expression() {
Node result = term();
while (peek() != null && (peek().getType() == TokenType.PLUS || peek().getType() == TokenType.MINUS)) {
Token token = matchAndRemove(peek().getType());
Node right = term();
if (right == null) {
throw new SyntaxErrorException("Expected right operand after " + token.getValue());
}
result = new MathOpNode(token.getType(), result, right);
}
return result;
}
private Node term() {
Node result = factor();
while (peek() != null && (peek().getType() == TokenType.TIMES || peek().getType() == TokenType.DIVIDE || peek().getType() == TokenType.MOD)) {
Token token = matchAndRemove(peek().getType());
Node right = factor();
if (right == null) {
throw new SyntaxErrorException("Expected right operand after " + token.getValue());
}
result = new MathOpNode(token.getType(), result, right);
}
return result;
}
private Node factor() {
Token token = matchAndRemove(TokenType.MINUS);
Node result = null;
if (peek() != null) {
if (peek().getType() == TokenType.NUMBER) {
Token numberToken = matchAndRemove(TokenType.NUMBER);
if (token != null) {
result = new IntegerNode(-Integer.parseInt(numberToken.getValue()));
} else {
result = new IntegerNode(Integer.parseInt(numberToken.getValue()));
}
} else if (peek().getType() == TokenType.IPAR) {
matchAndRemove(TokenType.IPAR);
result = expression();
expect(TokenType.RPAR);
}
}
return result;
}
private Token matchAndRemove(TokenType type) {
if (peek() != null && peek().getType() == type) {
currentTokenIndex++;
return tokens.get(currentTokenIndex - 1);
}
return null;
}
private void expect(TokenType type) throws SyntaxErrorException {
Token token = matchAndRemove(type);
if (token == null) {
throw new SyntaxErrorException("Expected " + type.toString());
}
}
private void expectEndOfLine() throws SyntaxErrorException {
expect(TokenType.ENDOFLINE);
}
private Token peek() {
return currentTokenIndex < tokens.size() ? tokens.get(currentTokenIndex) : null;
}
}

The Parser class in Java is an abstract class that provides the basic methods for processing input from a stream of characters. It is used for reading and manipulating text in applications. The Parser class provides methods for parsing data from a stream of characters, and for transforming that data into objects. It can be used to parse text from XML documents and from HTML documents, as well as from other sources. The most commonly used implementation of the Parser class is the org.xml.sax.Parser class, which is used to parse data from an XML document.

Trending nowThis is a popular solution!

Step by stepSolved in 3 steps



- Implement the transaction manager class using java Explain your code in few words. I have included other classes that have relation with the parking transaction calssarrow_forwardWritten in Python It should have an init method that takes two values and uses them to initialize the data members. It should have a get_age method. Docstrings for modules, functions, classes, and methodsarrow_forwardJava Code: Create a Parser class. Much like the Lexer, it has a constructor that accepts a LinkedList of Token and creates a TokenManager that is a private member. The next thing that we will build is a helper method – boolean AcceptSeperators(). One thing that is always tricky in parsing languages is that people can put empty lines anywhere they want in their code. Since the parser expects specific tokens in specific places, it happens frequently that we want to say, “there HAS to be a “;” or a new line, but there can be more than one”. That’s what this function does – it accepts any number of separators (newline or semi-colon) and returns true if it finds at least one. Create a Parse method that returns a ProgramNode. While there are more tokens in the TokenManager, it should loop calling two other methods – ParseFunction() and ParseAction(). If neither one is true, it should throw an exception. bool ParseFunction(ProgramNode) bool ParseAction(ProgramNode) -Creates ProgramNode,…arrow_forward
- public class PokerAnalysis implements PokerAnalyzer { privateList<Card>cards; privateint[]rankCounts; privateint[]suitCounts; /** * The constructor has been partially implemented for you. cards is the * ArrayList where you'll be adding all the cards you're given. In addition, * there are two arrays. You don't necessarily need to use them, but using them * will be extremely helpful. * * The rankCounts array is of the same length as the number of Ranks. At * position i of the array, keep a count of the number of cards whose * rank.ordinal() equals i. Repeat the same with Suits for suitCounts. For * example, if your Cards are (Clubs 4, Clubs 10, Spades 2), your suitCounts * array would be {2, 0, 0, 1}. * * @param cards * the list of cards to be added */ publicPokerAnalysis(List<Card>cards){ this.cards=newArrayList<Card>(); this.rankCounts=newint[Rank.values().length]; this.suitCounts=newint[Suit.values().length];…arrow_forwardpackage lab1; /** * A utility class containing several recursive methods * * <pre> * * For all methods in this API, you are forbidden to use any loops, * String or List based methods such as "contains", or methods that use regular expressions * </pre> * * */ public final class Lab1 { /** * This is empty by design, Lab class cannot be instantiated */ privateLab1(){ // empty by design } /** * Returns the product of a consecutive set of numbers from <code> start </code> * to <code> end </code>. * * @param start is an integer number * @param end is an integer number * @return the product of start * (start + 1) * ..*. + end * @pre. * <code> start </code> and <code> end </code> are small enough to let * this method return an int. This means the return value at most * requires 4 bytes and no overflow would happen. */ publicstaticintproduct(ints,inte){ if(s==e){ returne; }else{ returns*product(s+1,e); } }…arrow_forwardThe play method in the Player class of the craps game plays an entire game without interaction with the user. Revise the Player class so that its user can make individual rolls of the dice and view the results after each roll. The Player class no longer accumulates a list of rolls, but saves the string representation of each roll after it is made. Add new methods rollDice, getNumberOfRolls, isWinner, and isLoser to the Player class. The last three methods allow the user to obtain the number of rolls and to determine whether there is a winner or a loser. The last two methods are associated with new Boolean instance variables (winner and loser respectively). Two other instance variables track the number of rolls and the string representation of the most recent roll (rollsCount and roll). Another instance variable (atStartup) tracks whether or not the first roll has occurred. At instantiation, the roll, rollsCount, atStartup, winner, and loser variables are set to their appropriate…arrow_forward
- Java Programming: Make AST Nodes: IfNode, WhileNode, RepeatNode. All will have BooleanCompare for a condition and a collection of StatementNode. ForNode will have a Node for from and a node for to. This will have to be of type Node because it could be any expression. For example: for a from 1+1 to c-6 Make parsing functions for each. Java won't let you create methods called if(), etc. parseIf() is an example of a way around that; use whatever you like but use good sense in your names. Next let's look at function calls. Each function has a name and a collection of parameters. A parameter can be a VAR variable or something that came from booleanCompare (IntegerNode, VariableReferenceNode, etc). It would be reasonable to make 2 objects - ParameterVariableNode and ParameterExpressionNode. But for this very simple and well-defined case, we can do something simple: ParameterNode has a VariableReferenceNode (for VAR IDENTIFIER) and a Node for the case where the parameter is not a VAR.…arrow_forwardTask 3: Implement method setup in PE1 class. The description of what is wanted is given in the starter code. TASK 1 and 2 are done in class maze. Please use PE1 class. public class PE1 { MazedogMaze; /** * This method sets up the maze using the given input argument * @param maze is a maze that is used to construct the dogMaze */ publicvoidsetup(String[][]maze){ /* insert your code here to create the dogMaze * using the input argument. */ } /** * This method returns true if the number of * gates in dogMaze >= 2. * @return it returns true, if enough gate exists (at least 2), otherwise false. */ publicbooleanenoughGate(){ // insert your code here. Change the return value to fit your purpose. if() returntrue; } /** * This method finds a path from the entrance gate to * the exit gate. * @param row is the index of the row, where the entrance is. * @param column is the index of the column, where the entrance is. * @return it returns a string that contains the…arrow_forwardJava Programing Design class CarInLine, with the following specifications: The class has two instance variables: arrivalTime and DepartureTime, stored as integers. Define a constructor that accepts an integer as an argument representing the arrival time, in which you set the departure time to zero, marking the beginning of a simulation. Create an appropriate set and get methods for the two instance variables. Implement a method totalTime() that returns an integer value representing the time spent in the queue, as the difference between the departure time and the arrival time. Define ten queues, simulating the functionality of the process, increasing the number of cashiers from one, and collecting the average waiting time for each scenario. Each simulation will work with the same number of cars, which is considered 100. The maximum number of cashiers/toll booths is 10. Create the queue with link-based implementation. Create each queue with the corresponding number of cashiers,…arrow_forward
- Change the __str__ method of the Queue class (provided below) so that it prints each object in the queue along with its order in the queue (see sample output below). class Queue(): def __init__(self): self.queue = [] # implement with Python lists! # start of physical Python list == front of a queue # end of physical Python list == back of a queue def enqueue(self, new_obj): self.queue.append(new_obj); def dequeue(self): return self.queue.pop(0) def peek(self): return self.queue[0] def bad_luck(self): return self.queue[-1] def __str__(self): return str(self.queue) # let's try a more fun waySample output: >>> my_queue = Queue()>>> everyone = ["ESC", "ABC", "YOLO", "HTC"]>>> for initials in everyone:>>> my_queue.enqueue(initials)>>> print(my_queue)Output: 1: ESC2: ABC3: YOLO4: HTCarrow_forwardProblem 7: Assume that a queue class called XQueue has a no argument constructor, an enqueue() method, a dequeue() method and an isEmpty() method. Write a method that merges two given queues by copying the elements in an alternating sequence and returning the resulting combined queue. Note: make sure that you don't include unnecessary spaces in your answer! public XQueue merge(XQueue q1, XQueue q2) { XQueue neWQueue = new XQueue(); while (!q1.isEmpty() && !q2.isEmpty()) { newQueue.enqueue( #01 ); newQueue.enqueue( #02); } while (!q1.isEmpty()) { #03 ; } while (!q2.is Empty()) { #04 ; } return newQueue (); }arrow_forwardAssume we have an IntBST class, which implements a binary search tree of integers. The field of the class is a Node variable called root that refers to the root element of the tree. 1) Write a recursive method for this class that computes and returns the sum of all integers less than the root element. Assume the tree is not empty and there is at least one element less than the root. 2) Write a recursive method that prints all of the leaves, and only the leaves, of a binary search tree. 3) Write a method, using recursion or a loop, that returns the smallest element in the tree.arrow_forward
- Database System ConceptsComputer ScienceISBN:9780078022159Author:Abraham Silberschatz Professor, Henry F. Korth, S. SudarshanPublisher:McGraw-Hill Education
 Starting Out with Python (4th Edition)Computer ScienceISBN:9780134444321Author:Tony GaddisPublisher:PEARSON
Starting Out with Python (4th Edition)Computer ScienceISBN:9780134444321Author:Tony GaddisPublisher:PEARSON Digital Fundamentals (11th Edition)Computer ScienceISBN:9780132737968Author:Thomas L. FloydPublisher:PEARSON
Digital Fundamentals (11th Edition)Computer ScienceISBN:9780132737968Author:Thomas L. FloydPublisher:PEARSON  C How to Program (8th Edition)Computer ScienceISBN:9780133976892Author:Paul J. Deitel, Harvey DeitelPublisher:PEARSON
C How to Program (8th Edition)Computer ScienceISBN:9780133976892Author:Paul J. Deitel, Harvey DeitelPublisher:PEARSON Database Systems: Design, Implementation, & Manag...Computer ScienceISBN:9781337627900Author:Carlos Coronel, Steven MorrisPublisher:Cengage Learning
Database Systems: Design, Implementation, & Manag...Computer ScienceISBN:9781337627900Author:Carlos Coronel, Steven MorrisPublisher:Cengage Learning Programmable Logic ControllersComputer ScienceISBN:9780073373843Author:Frank D. PetruzellaPublisher:McGraw-Hill Education
Programmable Logic ControllersComputer ScienceISBN:9780073373843Author:Frank D. PetruzellaPublisher:McGraw-Hill Education