
Concept explainers
Videos
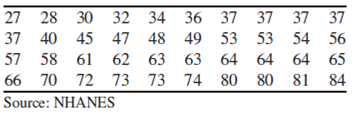
Cholesterol levels: The National Health and Nutrition Examination Survey (NHANES) measured the serum HDL cholesterol levels in a large number of women. Following is a sample of 40 HDL levels (in milligrams per deciliter) that are based on the results of that survey. They have been sorted into numerical order.
- a. Find the first and third
quartiles of these data. - b. Find the
median of these data. - c. Find the upper and lower outlier boundaries.
- d. Are there any outliers? If so, list them.
- e. Construct a boxplot for these data.
- f. Describe the shape of this distribution.
- g. What is the 20th percentile?
- h. What is the 67th percentile?
- i. One woman had a cholesterol level of 58. What percentile is this?
a.
Find the first and the third quartiles.
Answer to Problem 26E
The first and the third quartiles are 37 and 65.5 respectively.
Explanation of Solution
Calculation:
- The given information is a sample of 40 HDL cholesterol level obtained from the survey.
Three quartiles:
- The first quartile separates the lowest 25% of the observations from the other 75% of the observations. The first quartile is denoted by Q1.
- The second quartile separates the lower 50% of the observations from the other 50% of the observations. The second quartile is denoted by Q2. The second quartile is same as median.
- The third quartile separates the lowest 75% of the observations from the other 25% of the observations. The third quartile is denoted by Q3.
- Procedure for finding the first and the third quartile:
- Step 1: The observations should be arranged in increasing order.
- Step 2: The size of the data is n.
- For finding first quartile, L=0.25n
- For finding third quartile, L=0.75n
- Step 3: The quartile will be the average of the observation of the position L and the observation in position L+1, if L is a whole number. If the L value is not a whole number, the next higher whole number will be considered. The quartile is the observation in the position of rounded-up value.
- The observations are arranged in increasing order:
| 27 | 28 | 30 | 32 | 34 | 36 | 37 | 37 | 37 | 37 |
| 37 | 40 | 45 | 47 | 48 | 49 | 53 | 53 | 54 | 56 |
| 57 | 58 | 61 | 62 | 63 | 63 | 64 | 64 | 64 | 65 |
| 66 | 70 | 72 | 73 | 73 | 74 | 80 | 80 | 81 | 84 |
- The size of the data is n=40.
- For finding first quartile,
- L=0.25×40=10
- Here, 10 is a whole number, hence the 1st quartile will be the observation of the average of 10th and the 11th observations.
- From the arranged observations the first quartile is 37+372=37 .
- For finding third quartile,
- L=0.75×40=30
- Here, 30 is a whole number, hence the 3rd quartile will be the observation of the average of 30th and the 31st observations.
- From the arranged observations the third quartile is 65+662=65.5.
Hence, the first and the third quartiles are 37 and 65.5 respectively.
b.
Find the median of the data.
Answer to Problem 26E
The median of the data is 56.5.
Explanation of Solution
Calculation:
Median:
Let x1,x2...xn be n values.
The steps for finding the median:
- The all data values should be arranged in ascending order.
- If the total number of data values, n is odd, then the median will be the middle value or if n is even, then the median will be the average of middle two values.
- The observations are arranged in increasing order:
| 27 | 28 | 30 | 32 | 34 | 36 | 37 | 37 | 37 | 37 |
| 37 | 40 | 45 | 47 | 48 | 49 | 53 | 53 | 54 | 56 |
| 57 | 58 | 61 | 62 | 63 | 63 | 64 | 64 | 64 | 65 |
| 66 | 70 | 72 | 73 | 73 | 74 | 80 | 80 | 81 | 84 |
- The size of the data is 40. That is, n=40.
- Hence, the sample size is even. Therefore, the median is the average of 20th and 21st observation.
- From the arranged observations the median is 56+572=56.5
Thus, the median of the data is 56.5.
c.
Find the lower and upper outlier boundaries.
Answer to Problem 26E
The lower and upper outlier boundaries are –5.75 and 108.25 respectively.
Explanation of Solution
Calculation:
Interquartile range:
- The interquartile range is the difference between the third quartile and first quartile. For detecting outlier this measure can be used.
- Interquartile range can be found as, IQR=Q3−Q1. Where, the first quartile is denoted by Q1 and third quartile is denoted by Q3.
- From part (a), the first and the third quartiles are 37 and 65.5 respectively.
- Substitute these values in the interquartile range formula,
- IQR=65.5−37=28.5
- Outlier boundaries:
- Lower outlier boundary is Q1−1.5×IQR.
- Upper outlier boundary is Q3+1.5×IQR.
- Where, the first quartile is denoted by Q1 and third quartile is denoted by Q3.
- Substitute these values in the formulae,
- Lower outlier boundary=37−1.5×28.5=37−42.75=−5.75.
- Upper outlier boundary=65.5+1.5×28.5=65.5+42.75=108.25
Thus, the lower and upper outlier boundaries are –5.75 and 108.25 respectively.
d.
Find the outliers.
Answer to Problem 26E
There is no outlier in the data.
Explanation of Solution
Calculation:
- Condition for outlier:
- If any observation is less than the lower outlier boundary, the observation will be outlier.
- If any observation is greater than the upper outlier boundary, the observation will be outlier.
From part (c), the lower and upper outlier boundaries are –5.75 and 108.25 respectively.
In the given data, all observations are greater than the lower outlier boundary and less than the upper outlier boundary.
Hence, there is no outlier in the data.
e.
Draw a boxplot of the data.
Answer to Problem 26E
The boxplot is given below,
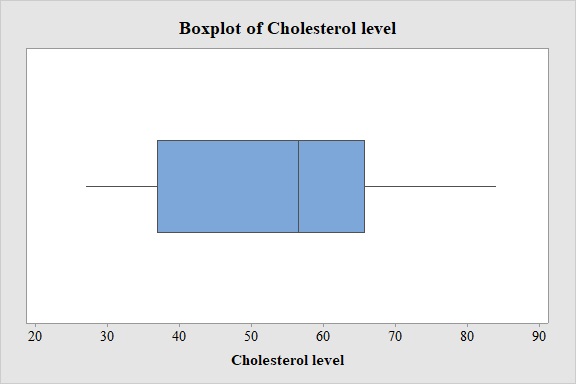
Explanation of Solution
Calculation:
- Boxplot:
Software procedure:
- Step-by-step procedure to draw a boxplot using the MINITAB software:
- Choose Graph > Boxplot.
- Choose Simple. Click OK.
- In Graph variables, enter the data of Cholesterol level.
- Click OK.
Output using the MINITAB software is given below:
- From the MINITAB output, it is clear that there is no outlier in the data.
f.
Explain the shape of the distribution.
Answer to Problem 26E
The data is slightly left skewed or it can be said that approximately symmetric.
Explanation of Solution
The rule for determining the skewness from the Boxplot:
- The data is right skewed if the median is closer to the 1st quartile than the 3rd quartile or the upper whisker is longer than the lower whisker.
- The data is left skewed if the median is closer to the 3rd quartile than the 1st quartile or the lower whisker is longer than the upper whisker.
- The data is approximately symmetric if the median is the middle point of 1st quartile and the 3rd quartile or the length of the upper whisker and the lower whisker is approximately same.
From the Boxplot of part (e), is clear that the median is slightly closer to the 3rd quartile than the 1st quartile, in other words, the upper whisker is slightly longer than the lower whisker.
By using the above rule, it can be said that the data is slightly left skewed or it can be said that approximately symmetric.
g.
Find the 20th percentile of the data.
Answer to Problem 26E
The 20th percentile is 37.
Explanation of Solution
Calculation:
pth percentile:
The pth percentile separates the lowest p% of the observations from the highest (100−p)% of the observations. 1<p<100 .
Procedure for finding pth percentile:
- Step 1: The observations should be arranged in increasing order.
- Step 2: The size of the data is n.
For finding pth percentile, L=p100n
- Step 3: The pth percentile will be the average of the observation of the position L and the observation in position L+1, if L is a whole number. If the L value is not a whole number, the next higher whole number will be considered. The pth percentile is the observation in the position of rounded-up value.
- The observations are arranged in increasing order:
| 27 | 28 | 30 | 32 | 34 | 36 | 37 | 37 | 37 | 37 |
| 37 | 40 | 45 | 47 | 48 | 49 | 53 | 53 | 54 | 56 |
| 57 | 58 | 61 | 62 | 63 | 63 | 64 | 64 | 64 | 65 |
| 66 | 70 | 72 | 73 | 73 | 74 | 80 | 80 | 81 | 84 |
- The size of the data is n=40.
- For finding 20th percentile,
- L=20100×40=8
- Here, 8 is a whole number, hence the 20th percentile will be the average of the observations in the position of 8th and 9th.
- From the arranged observations the 20th percentile is 37+372=37.
Hence, the 20th percentile is 37.
h.
Find the 67th percentile of the data.
Answer to Problem 26E
The 67th percentile is 64.
Explanation of Solution
Calculation:
- The observations are arranged in increasing order:
| 27 | 28 | 30 | 32 | 34 | 36 | 37 | 37 | 37 | 37 |
| 37 | 40 | 45 | 47 | 48 | 49 | 53 | 53 | 54 | 56 |
| 57 | 58 | 61 | 62 | 63 | 63 | 64 | 64 | 64 | 65 |
| 66 | 70 | 72 | 73 | 73 | 74 | 80 | 80 | 81 | 84 |
- The size of the data is n=40.
- For finding 67th percentile,
- L=67100×40=26.80
- Here, 26.8 is not a whole number, hence the 67th percentile will be the observation in the 27th position.
- From the arranged observations the 67th percentile is 64.
Hence, the 67th percentile is 64.
i.
Find the percentile for the given cholesterol level.
Answer to Problem 26E
The value is of 54th percentile.
Explanation of Solution
Calculation:
It is given that a woman had a cholesterol level of 58.
Procedure for finding the percentile for a given observation:
- The observations should be arranged in ascending order.
- If the observation is x, then the percentile of the observation is,
Perentile=100×(Number of values less than x)+0.5Number of values in the data set
If the value is not a whole number the nearest whole number will be the percentile.
- The observations are arranged in increasing order:
| 27 | 28 | 30 | 32 | 34 | 36 | 37 | 37 | 37 | 37 |
| 37 | 40 | 45 | 47 | 48 | 49 | 53 | 53 | 54 | 56 |
| 57 | 58 | 61 | 62 | 63 | 63 | 64 | 64 | 64 | 65 |
| 66 | 70 | 72 | 73 | 73 | 74 | 80 | 80 | 81 | 84 |
Here, x=58.
From the observations, it is clear that there are 21 observations which are less than 58. Total number of observation is 40.
Hence, the percentile is,
Perentile=100×21+0.540=21.540×100=53.75
- Here, 53.75 is not a whole number, hence value is in 54th percentile.
Hence, the value is of 54th percentile.
Want to see more full solutions like this?
Chapter 3 Solutions
Essential Statistics


- Exercise 6-6 (Algo) (LO6-3) The director of admissions at Kinzua University in Nova Scotia estimated the distribution of student admissions for the fall semester on the basis of past experience. Admissions Probability 1,100 0.5 1,400 0.4 1,300 0.1 Click here for the Excel Data File Required: What is the expected number of admissions for the fall semester? Compute the variance and the standard deviation of the number of admissions. Note: Round your standard deviation to 2 decimal places.arrow_forward1. Find the mean of the x-values (x-bar) and the mean of the y-values (y-bar) and write/label each here: 2. Label the second row in the table using proper notation; then, complete the table. In the fifth and sixth columns, show the 'products' of what you're multiplying, as well as the answers. X y x minus x-bar y minus y-bar (x minus x-bar)(y minus y-bar) (x minus x-bar)^2 xy 16 20 34 4-2 5 2 3. Write the sums that represents Sxx and Sxy in the table, at the bottom of their respective columns. 4. Find the slope of the Regression line: bi = (simplify your answer) 5. Find the y-intercept of the Regression line, and then write the equation of the Regression line. Show your work. Then, BOX your final answer. Express your line as "y-hat equals...arrow_forwardApply STATA commands & submit the output for each question only when indicated below i. Generate the log of birthweight and family income of children. Name these new variables Ibwght & Ifaminc. Include the output of this code. ii. Apply the command sum with the detail option to the variable faminc. Note: you should find the 25th percentile value, the 50th percentile and the 75th percentile value of faminc from the output - you will need it to answer the next question Include the output of this code. iii. iv. Use the output from part ii of this question to Generate a variable called "high_faminc" that takes a value 1 if faminc is less than or equal to the 25th percentile, it takes the value 2 if faminc is greater than 25th percentile but less than or equal to the 50th percentile, it takes the value 3 if faminc is greater than 50th percentile but less than or equal to the 75th percentile, it takes the value 4 if faminc is greater than the 75th percentile. Include the outcome of this code…arrow_forward
- solve this on paperarrow_forwardApply STATA commands & submit the output for each question only when indicated below i. Apply the command egen to create a variable called "wyd" which is the rowtotal function on variables bwght & faminc. ii. Apply the list command for the first 10 observations to show that the code in part i worked. Include the outcome of this code iii. Apply the egen command to create a new variable called "bwghtsum" using the sum function on variable bwght by the variable high_faminc (Note: need to apply the bysort' statement) iv. Apply the "by high_faminc" statement to find the V. descriptive statistics of bwght and bwghtsum Include the output of this code. Why is there a difference between the standard deviations of bwght and bwghtsum from part iv of this question?arrow_forwardAccording to a health information website, the distribution of adults’ diastolic blood pressure (in millimeters of mercury, mmHg) can be modeled by a normal distribution with mean 70 mmHg and standard deviation 20 mmHg. b. Above what diastolic pressure would classify someone in the highest 1% of blood pressures? Show all calculations used.arrow_forward
- Write STATA codes which will generate the outcomes in the questions & submit the output for each question only when indicated below i. ii. iii. iv. V. Write a code which will allow STATA to go to your favorite folder to access your files. Load the birthweight1.dta dataset from your favorite folder and save it under a different filename to protect data integrity. Call the new dataset babywt.dta (make sure to use the replace option). Verify that it contains 2,998 observations and 8 variables. Include the output of this code. Are there missing observations for variable(s) for the variables called bwght, faminc, cigs? How would you know? (You may use more than one code to show your answer(s)) Include the output of your code (s). Write the definitions of these variables: bwght, faminc, male, white, motheduc,cigs; which of these variables are categorical? [Hint: use the labels of the variables & the browse command] Who is this dataset about? Who can use this dataset to answer what kind of…arrow_forwardApply STATA commands & submit the output for each question only when indicated below İ. ii. iii. iv. V. Apply the command summarize on variables bwght and faminc. What is the average birthweight of babies and family income of the respondents? Include the output of this code. Apply the tab command on the variable called male. How many of the babies and what share of babies are male? Include the output of this code. Find the summary statistics (i.e. use the sum command) of the variables bwght and faminc if the babies are white. Include the output of this code. Find the summary statistics (i.e. use the sum command) of the variables bwght and faminc if the babies are male but not white. Include the output of this code. Using your answers to previous subparts of this question: What is the difference between the average birthweight of a baby who is male and a baby who is male but not white? What can you say anything about the difference in family income of the babies that are male and male…arrow_forwardA public health researcher is studying the impacts of nudge marketing techniques on shoppers vegetablesarrow_forward
- The director of admissions at Kinzua University in Nova Scotia estimated the distribution of student admissions for the fall semester on the basis of past experience. Admissions Probability 1,100 0.5 1,400 0.4 1,300 0.1 Click here for the Excel Data File Required: What is the expected number of admissions for the fall semester? Compute the variance and the standard deviation of the number of admissions. Note: Round your standard deviation to 2 decimal places.arrow_forwardA pollster randomly selected four of 10 available people. Required: How many different groups of 4 are possible? What is the probability that a person is a member of a group? Note: Round your answer to 3 decimal places.arrow_forwardWind Mountain is an archaeological study area located in southwestern New Mexico. Potsherds are broken pieces of prehistoric Native American clay vessels. One type of painted ceramic vessel is called Mimbres classic black-on-white. At three different sites the number of such sherds was counted in local dwelling excavations. Test given. Site I Site II Site III 63 19 60 43 34 21 23 49 51 48 11 15 16 46 26 20 31 Find .arrow_forward
 Big Ideas Math A Bridge To Success Algebra 1: Stu...AlgebraISBN:9781680331141Author:HOUGHTON MIFFLIN HARCOURTPublisher:Houghton Mifflin Harcourt
Big Ideas Math A Bridge To Success Algebra 1: Stu...AlgebraISBN:9781680331141Author:HOUGHTON MIFFLIN HARCOURTPublisher:Houghton Mifflin Harcourt Glencoe Algebra 1, Student Edition, 9780079039897...AlgebraISBN:9780079039897Author:CarterPublisher:McGraw Hill
Glencoe Algebra 1, Student Edition, 9780079039897...AlgebraISBN:9780079039897Author:CarterPublisher:McGraw Hill Holt Mcdougal Larson Pre-algebra: Student Edition...AlgebraISBN:9780547587776Author:HOLT MCDOUGALPublisher:HOLT MCDOUGAL
Holt Mcdougal Larson Pre-algebra: Student Edition...AlgebraISBN:9780547587776Author:HOLT MCDOUGALPublisher:HOLT MCDOUGAL