
Related questions
Hello,
Please read the provided text carefully—everything is detailed there.
I need high-quality diagrams for both cases: Student A and Student B, showing the teacher teaching them through knowledge distillation.
Each case should be represented as a separate image.
The knowledge distillation process must be clearly illustrated in both.
I’ve attached an image that shows the level of clarity I’m aiming for.
Please do not use AI-generated diagrams.
If I wanted that, I could do it myself using ChatGPT Premium.
I’m looking for support from a real human expert—and I know you can help.
"
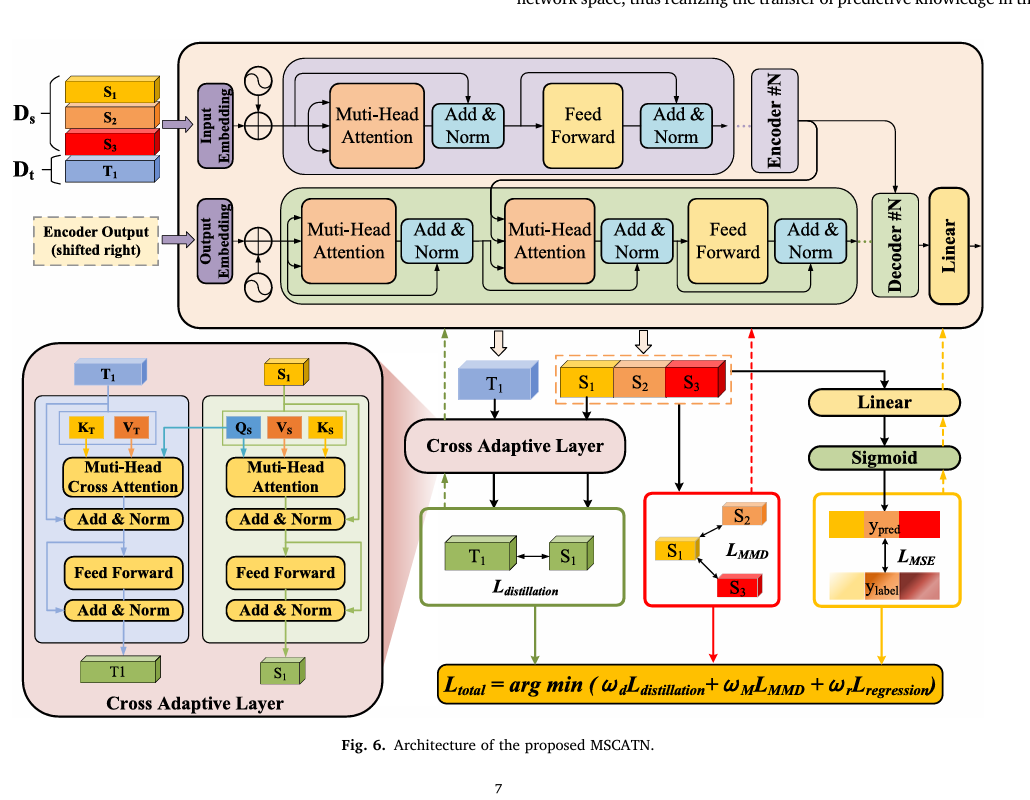
1. Teacher Model Architecture (T)
Dataset C: Clean data with complete inputs and labels
Architecture
Input Embedding Layer
Converts multivariate sensor inputs into dense vectors.
Positional Encoding
Adds time-step order information to each embedding.
Transformer Encoder Stack (repeated N times)
Multi-Head Self-Attention: Captures temporal dependencies across time steps.
Add & Norm: Applies residual connections and layer normalization.
Feedforward Network: Applies MLP with non-linearity (e.g., ReLU or GELU).
Feature Representation Layer (F_T)
Intermediate latent feature vector used for feature distillation.
Regression Head
Linear layer that outputs the final RUL prediction y_T.
Learning Objective
Supervised loss with ground truth RUL.
Provide F_T and y_T as guidance to student models.
2. Student A Architecture – Handling Missing Inputs
Dataset A: Incomplete inputs, complete RUL labels
Architecture
Masked Input Embedding Layer
Maps inputs with missing values into dense vectors.
Missing values are masked or replaced with a learned token.
Positional Encoding
Adds time-step information to each embedding.
Transformer Encoder Stack (N layers)
Multi-Head Self-Attention
Learns dependencies among available channels and ignores masked ones.
Add & Norm
Feedforward Layer
Feature Representation Layer (F_A)
Used for feature distillation against F_T.
Regression Head
Predicts RUL → y_A.
Knowledge Distillation
Feature Distillation
Mean Squared Error between F_A and F_T.
Prediction Distillation
MSE or KL divergence between y_A and y_T.
Supervised Loss
Ground truth RUL is available.
Total Loss
Ltotal_A=Lsup(yA,ytrue)+λ1⋅Lfeature(FA,FT)+λ2⋅Lpred(yA,yT)L_{\text{total\_A}} = L_{\text{sup}}(y_A, y_{\text{true}}) + \lambda_1 \cdot L_{\text{feature}}(F_A, F_T) + \lambda_2 \cdot L_{\text{pred}}(y_A, y_T)
3. Student B Architecture – Handling Missing Labels
Dataset B: Complete inputs, partial RUL labels
Architecture
Input Embedding Layer
Dense transformation of sensor values.
Positional Encoding
Adds sequential time-step information.
Transformer Encoder Stack (N layers)
Multi-Head Self-Attention
Add & Norm
Feedforward Layer
Regression Head
Predicts RUL → y_B
Knowledge Distillation
Prediction Distillation Only
For unlabeled samples: use y_T as pseudo-labels
For labeled samples: use supervised loss
Total Loss
Ltotal_B=Lsup(yB,ytrue)+λ3⋅Lpred(yB,yT)L_{\text{total\_B}} = L_{\text{sup}}(y_B, y_{\text{true}}) + \lambda_3 \cdot L_{\text{pred}}(y_B, y_T)


Step by stepSolved in 2 steps with 2 images


- Computer Networking: A Top-Down Approach (7th Edi...Computer EngineeringISBN:9780133594140Author:James Kurose, Keith RossPublisher:PEARSON
 Computer Organization and Design MIPS Edition, Fi...Computer EngineeringISBN:9780124077263Author:David A. Patterson, John L. HennessyPublisher:Elsevier Science
Computer Organization and Design MIPS Edition, Fi...Computer EngineeringISBN:9780124077263Author:David A. Patterson, John L. HennessyPublisher:Elsevier Science Network+ Guide to Networks (MindTap Course List)Computer EngineeringISBN:9781337569330Author:Jill West, Tamara Dean, Jean AndrewsPublisher:Cengage Learning
Network+ Guide to Networks (MindTap Course List)Computer EngineeringISBN:9781337569330Author:Jill West, Tamara Dean, Jean AndrewsPublisher:Cengage Learning  Concepts of Database ManagementComputer EngineeringISBN:9781337093422Author:Joy L. Starks, Philip J. Pratt, Mary Z. LastPublisher:Cengage Learning
Concepts of Database ManagementComputer EngineeringISBN:9781337093422Author:Joy L. Starks, Philip J. Pratt, Mary Z. LastPublisher:Cengage Learning Prelude to ProgrammingComputer EngineeringISBN:9780133750423Author:VENIT, StewartPublisher:Pearson Education
Prelude to ProgrammingComputer EngineeringISBN:9780133750423Author:VENIT, StewartPublisher:Pearson Education Sc Business Data Communications and Networking, T...Computer EngineeringISBN:9781119368830Author:FITZGERALDPublisher:WILEY
Sc Business Data Communications and Networking, T...Computer EngineeringISBN:9781119368830Author:FITZGERALDPublisher:WILEY