
Database System Concepts
7th Edition
ISBN: 9780078022159
Author: Abraham Silberschatz Professor, Henry F. Korth, S. Sudarshan
Publisher: McGraw-Hill Education
expand_more
expand_more
format_list_bulleted
Related questions
Concept explainers
Question
Please answer with detail
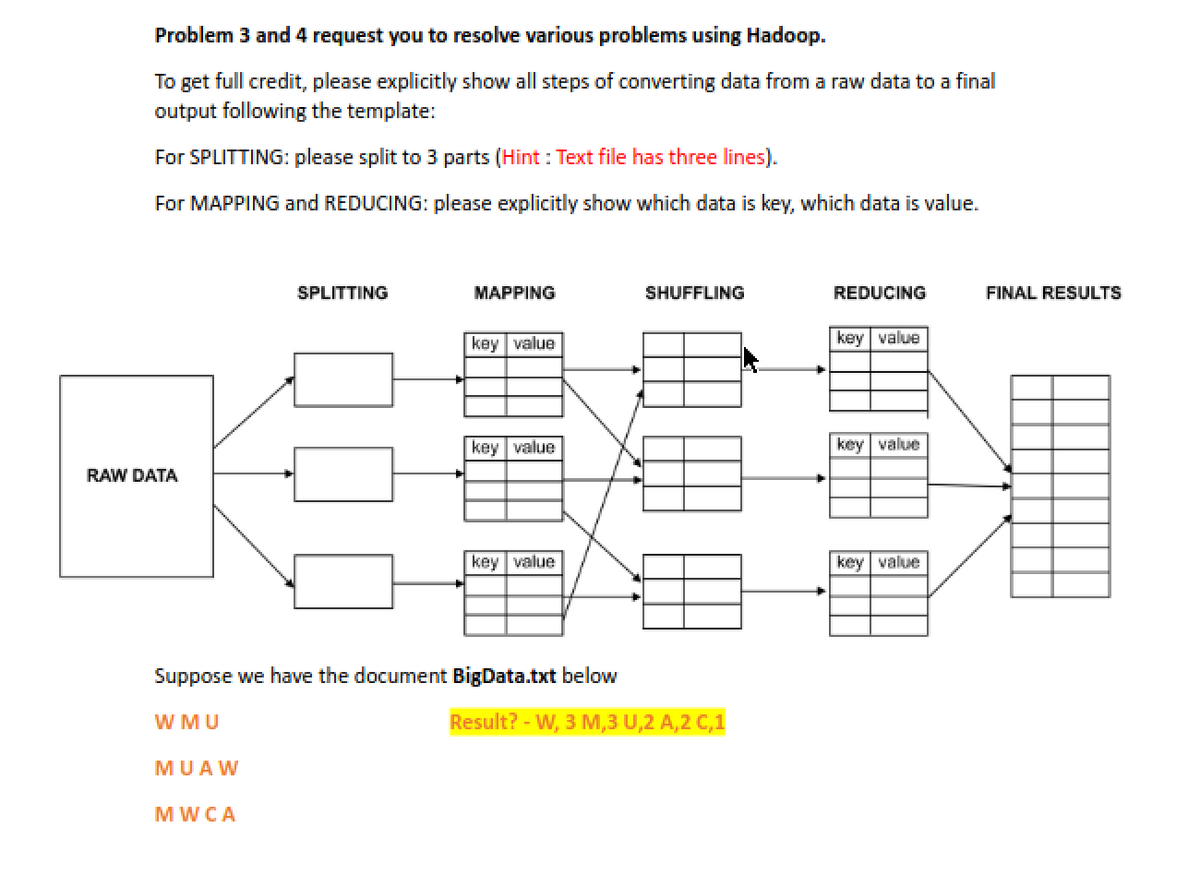

Transcribed Image Text:**Problem 3 and 4 request you to resolve various problems using Hadoop.**
To get full credit, please explicitly show all steps of converting data from raw data to a final output following the template:
For SPLITTING: please split to 3 parts (Hint: Text file has three lines).
For MAPPING and REDUCING: please explicitly show which data is key, which data is value.
### Diagram Explanation
The diagram illustrates the process of data transformation using Hadoop, which involves several stages:
1. **Splitting:**
- The raw data is divided into three parts. These sections represent different segments of the data to be processed.
2. **Mapping:**
- Each segment from the splitting step is processed individually.
- The data is mapped into key-value pairs, where each key is associated with a corresponding value.
3. **Shuffling:**
- The key-value pairs are reorganized based on the key. This step groups all values associated with similar keys together to ensure efficient data processing.
4. **Reducing:**
- The shuffled data undergoes reduction, where operations are performed on the values to produce a condensed output.
- Again, data is maintained in key-value pairs format.
5. **Final Results:**
- The reduced data is compiled into a final result set, representing the processed output.
### Example
Suppose we have the document **BigData.txt** below:
```
W M U
M U A W
M W C A
```
**Expected Result:**
- W, 3
- M, 3
- U, 2
- A, 2
- C, 1
This output implies that the letter 'W' appears 3 times, 'M' appears 3 times, 'U' appears 2 times, 'A' appears 2 times, and 'C' appears 1 time after processing through Hadoop.

Transcribed Image Text:**Problem 4: Indicating the <Key, Value> pairs in each phase of data processing in Hadoop**
Please write each step in bullet points or by drawing diagrams to get the top 2 most frequent keywords in BigData.txt using Hadoop.
Expert Solution
This question has been solved!
Explore an expertly crafted, step-by-step solution for a thorough understanding of key concepts.

This is a popular solution

Trending nowThis is a popular solution!

Step by stepSolved in 2 steps with 1 images

Knowledge Booster


Learn more about
Need a deep-dive on the concept behind this application? Look no further. Learn more about this topic, computer-science and related others by exploring similar questions and additional content below.Similar questions
- By studying an item's bounding box in the Designer, you may get insight into the attributes of the object in a number of different ways.arrow_forwardExplain the concept of a dictionary in programming languages and provide an example of how dictionaries are used in Python.arrow_forwardDescribe three circumstances when a surrogate key for the primary key of a relation should be created.arrow_forward
arrow_back_ios
SEE MORE QUESTIONS
arrow_forward_ios
Recommended textbooks for you
- Database System ConceptsComputer ScienceISBN:9780078022159Author:Abraham Silberschatz Professor, Henry F. Korth, S. SudarshanPublisher:McGraw-Hill Education
 Starting Out with Python (4th Edition)Computer ScienceISBN:9780134444321Author:Tony GaddisPublisher:PEARSON
Starting Out with Python (4th Edition)Computer ScienceISBN:9780134444321Author:Tony GaddisPublisher:PEARSON Digital Fundamentals (11th Edition)Computer ScienceISBN:9780132737968Author:Thomas L. FloydPublisher:PEARSON
Digital Fundamentals (11th Edition)Computer ScienceISBN:9780132737968Author:Thomas L. FloydPublisher:PEARSON  C How to Program (8th Edition)Computer ScienceISBN:9780133976892Author:Paul J. Deitel, Harvey DeitelPublisher:PEARSON
C How to Program (8th Edition)Computer ScienceISBN:9780133976892Author:Paul J. Deitel, Harvey DeitelPublisher:PEARSON Database Systems: Design, Implementation, & Manag...Computer ScienceISBN:9781337627900Author:Carlos Coronel, Steven MorrisPublisher:Cengage Learning
Database Systems: Design, Implementation, & Manag...Computer ScienceISBN:9781337627900Author:Carlos Coronel, Steven MorrisPublisher:Cengage Learning Programmable Logic ControllersComputer ScienceISBN:9780073373843Author:Frank D. PetruzellaPublisher:McGraw-Hill Education
Programmable Logic ControllersComputer ScienceISBN:9780073373843Author:Frank D. PetruzellaPublisher:McGraw-Hill Education
Database System Concepts
Computer Science
ISBN:9780078022159
Author:Abraham Silberschatz Professor, Henry F. Korth, S. Sudarshan
Publisher:McGraw-Hill Education
Starting Out with Python (4th Edition)
Computer Science
ISBN:9780134444321
Author:Tony Gaddis
Publisher:PEARSON
Digital Fundamentals (11th Edition)
Computer Science
ISBN:9780132737968
Author:Thomas L. Floyd
Publisher:PEARSON
C How to Program (8th Edition)
Computer Science
ISBN:9780133976892
Author:Paul J. Deitel, Harvey Deitel
Publisher:PEARSON
Database Systems: Design, Implementation, & Manag...
Computer Science
ISBN:9781337627900
Author:Carlos Coronel, Steven Morris
Publisher:Cengage Learning
Programmable Logic Controllers
Computer Science
ISBN:9780073373843
Author:Frank D. Petruzella
Publisher:McGraw-Hill Education