
Related questions
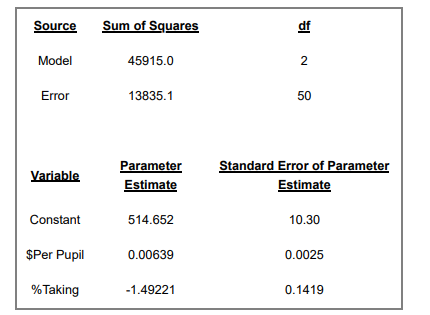
Please help me better understand word problem. A researcher was investigating variables that might be associated with the academic performance of high school students. The data included the average Math SAS score of all high school seniors in the city that took the exam (labeled as the variable SAT-M), the average number of dollars per pupil spent on education by the city (labeled as the variable $Per Pupil), and the percentage of high school seniors in the city that took the exam (labeled as the variable %Taking). As part of the researcher's investigation, he ran the following multiple linear regression model as SAT-M=Beta0 + Beta1($Per Pupil) + Beta2(%Taking). This model was fit to the data using the method of least-squares, results shown inside of table within photo.
Question: What's the 95% confidence interval for Beta1, (coefficient of variable $PerPupil). Then determine the interpretation for Beta2 (coefficient of %Taking variable).



Trending nowThis is a popular solution!

Step by stepSolved in 5 steps with 17 images


- An industrial psychologist hired by a leading accounting firm wanted to know if the average number of hours worked per week at the firm was significantly different from the national average of 52 hours for accountants. The industrial psychologist randomly sampled n=16 people from different divisions within the firm, and calculated the average number of hours they worked per week over a three-month period. The dependent variable in this study is the number of hours worked per week. The data he obtained were: 54, 48, 68, 53, 60, 45, 57, 62, 71, 60, 55, 63, 68, 64, 56, 60arrow_forwardIn a study looking at undergraduate students’ perceptions of sense of community at their university, a researcher hypothesizes that the farther away students live from campus (in miles), the less they feel they are part of the university community. The researcher collected data for the following two variables – miles from campus and part of community (rating from 1-10 of how much they felt part of the university community). Proposed analysis (the kind of test) and why you chose the analysis: Scales of measurement (i.e., nominal, ordinal, interval or ratio) for variable(s) that will be used in the analysis: Null and alternative hypotheses (based on context of study) in symbols: Test assumptions and make a decision Inferential statistic(s) and p-value(s): Decision: conclusion Based on your decision, identify and explain the type of error you could be making with respect to the conclusions of the studyarrow_forwardIs the height (in inches) of students in this class a quantitative or qualitative variable?arrow_forward
- In a study looking at undergraduate students’ perceptions of sense of community at their university, a researcher hypothesizes that the farther away students live from campus (in miles), the less they feel they are part of the university community. The researcher collected data for the following two variables – miles from campus and part of community (rating from 1-10 of how much they felt part of the university community). what is the scale of measurement? (i.e., nominal, ordinal, interval or ratio)arrow_forwardRefer to the following: For countries listed in the Human Development Report, the correlation between the percent of people using the Internet and per capita gross domestic product (GDP) is 0.888. The correlation (r) between the percent of people using the Internet and the percent using cell phones is 0.818. The correlation between the percent of people using the Internet and the literacy rate is 0.669. The correlation between the percent of people using the Internet and the fertility rate is -0.551. Which variable (GDP, percent using cell phones, literacy rate, or fertility rate) has the strongest linear association with Internet use? Which variable has the weakest linear association with Internet use?arrow_forwardEach year forbes ranks the world’s most valuable brands. A portion of the data for 82 ofthe brands in the 2013 forbes list is shown in Table 2.12 (forbes website, february, 2014).The data set includes the following variables:brand: The name of the brand.Industry: The type of industry associated with the brand, labeled Automotive& Luxury, Consumer Packaged Goods, financial Services, Other, Technology.brand Value ($ billions): A measure of the brand’s value in billions of dollarsdeveloped by forbes based on a variety of financial information about the brand.1-Yr Value Change (%): The percentage change in the value of the brand over theprevious year.brand Revenue ($ billions): The total revenue in billions of dollars for the brand.a. Prepare a crosstabulation of the data on Industry (rows) and brand Value ($ billions).Use classes of 0–10, 10–20, 20–30, 30–40, 40–50, and 50–60 for brand Value($ billions).b. Prepare a frequency distribution for the data on Industry.arrow_forward
- You saw back in Chapter 2 that the mean, median, mode, and midrange are used to indicate where data is centered in a data set, or in other words what a typical value in the set is. A question that is often asked is, "If they're all supposed to do the same thing, why is there more than one?" Isn't one enough? In this exercise, you will be given two small sets of data. For each set, a. find the mean, median, mode and midrange b. in your opinion, decide which of the measures BEST represents all the values in the set (best indicates a typical value), and which one does this the WORST. c. post your responses and justify them by explaining why Don't forget to respond to at least one of your classmate's posts. With this exercise, "more is better." I'll elaborate after the deadline. • Set A: the salaries of 10 employees at a company (in thousands of dollars): 50, 50, 50, 50, 50, 50, 50, 50, 50, 500 • Set B: the grades of 9 students on an exam: 20, 25, 30, 35, 40, 45, 100, 100, 100arrow_forwardSuppose you were to collect data for the following pair of variables, drivers: blood alcohol level, reaction time. You want to make a scatter plot. Which variable would you use as the explanatory variable? Blood alcohol or reaction time? Which variable would you use as the response variable? Blood alcohol or reaction time? Would you expect to see a positive or negative association? Or neither?arrow_forwardYou need to use Stata to look up the dataset and its variables. Use Stata Companion Textbook. (Dataset: NES. Variables: spend8, [pw=nesw].) The NES dataset contains spend8, which records the number of government policy areas where respondents think spending should be increased. Scores range from 0 (the respondent does not want to increase spending on any of the policies) to 8 (the respondent wants to increase spending on all eight policies). The NES, of course, polls a random sample of U.S. adults. In this exercise you will analyze spend8 using the mean and lincom commands. You then will draw inferences about the population mean. (Remember to specify nesw as the probability weight.) The spend8 variable has a sample mean of ______. Make sure you use [pw=nesw] so your results are nationally representative. There is a probability of .95 that spend8’s true population mean falls between a score of ______ at the low end and a score of ______ at the high end. A student researcher…arrow_forward
- A colleague of yours is faced with testing a relationship at the .05 level or significance or the .01 level of significance. What is your advice to your colleague? Why?arrow_forwardWhat is a confounding variable in research, and how can it affect the results of a study? Provide an example of a confounding variable in a hypothetical study.arrow_forwardA recent study on driving behavior examined whether the combination of high driving skills and low safety skills is dangerous. Participants were classified as high or low in driving skill based on responses to a driver-skill inventory, then classified as high or low in safety skill based on responses to a driver-aggression scale. An overall measure of driving risk was obtained by combining several variables such as number of accidents, tickets, tendency to speed, etc. The following data were obtained. Use a 2 x 2 ANOVA with the .05 significance level to evaluate the results. What cutoff score(s) should be used? Driving Skill Low High Safety Skill Low M1=5 M2=4.5 S1=2.7 S2=3.8 N1=6 N2=6 HIgh M3=3 M4=3.5 S3=2.9 S4=2.5 N3=6 N4=6 Group of answer choices +4.35 +3.40 +3.49 +4.26arrow_forward
- MATLAB: An Introduction with ApplicationsStatisticsISBN:9781119256830Author:Amos GilatPublisher:John Wiley & Sons Inc
 Probability and Statistics for Engineering and th...StatisticsISBN:9781305251809Author:Jay L. DevorePublisher:Cengage Learning
Probability and Statistics for Engineering and th...StatisticsISBN:9781305251809Author:Jay L. DevorePublisher:Cengage Learning Statistics for The Behavioral Sciences (MindTap C...StatisticsISBN:9781305504912Author:Frederick J Gravetter, Larry B. WallnauPublisher:Cengage Learning
Statistics for The Behavioral Sciences (MindTap C...StatisticsISBN:9781305504912Author:Frederick J Gravetter, Larry B. WallnauPublisher:Cengage Learning  Elementary Statistics: Picturing the World (7th E...StatisticsISBN:9780134683416Author:Ron Larson, Betsy FarberPublisher:PEARSON
Elementary Statistics: Picturing the World (7th E...StatisticsISBN:9780134683416Author:Ron Larson, Betsy FarberPublisher:PEARSON The Basic Practice of StatisticsStatisticsISBN:9781319042578Author:David S. Moore, William I. Notz, Michael A. FlignerPublisher:W. H. Freeman
The Basic Practice of StatisticsStatisticsISBN:9781319042578Author:David S. Moore, William I. Notz, Michael A. FlignerPublisher:W. H. Freeman Introduction to the Practice of StatisticsStatisticsISBN:9781319013387Author:David S. Moore, George P. McCabe, Bruce A. CraigPublisher:W. H. Freeman
Introduction to the Practice of StatisticsStatisticsISBN:9781319013387Author:David S. Moore, George P. McCabe, Bruce A. CraigPublisher:W. H. Freeman