Related questions
Question

Transcribed Image Text:1 crim
ΝΕ
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
Ready
A
0.00632
0.02731
0.02729
0.03237
0.06905
0.02985
0.08829
0.14455
0.21124
0.17004
0.22489
0.11747
0.09378
0.62976
0.63796
0.62739
1.05393
0.7842
0.80271
0.7258
1.25179
0.85204
1.23247
0.98843
0.75026
0.84054
0.67191
0.95577
0.77299
1.00245
1.13081
Boston
zn
18
0
0
0
0
0
12.5
12.5
12.5
12.5
12.5
12.5
12.5
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
indus
Accessibility: Unavailable
C
2.31
7.07
7.07
2.18
2.18
2.18
7.87
7.87
7.87
7.87
7.87
7.87
7.87
8.14
8.14
8.14
8.14
8.14
8.14
8.14
8.14
8.14
8.14
8.14
8.14
8.14
8.14
8.14
8.14
8.14
8.14
chas
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
nox
E
0.538
0.469
0.469
0.458
0.458
0.458
0.524
0.524
0.524
0.524
0.524
0.524
0.524
0.538
0.538
0.538
0.538
0.538
0.538
0.538
0.538
0.538
0.538
0.538
0.538
0.538
0.538
0.538
0.538
0.538
0.538
rm
F
6.575
6.421
7.185
6.998
7.147
6.43
6.012
6.172
5.631
6.004
6.377
6.009
5.889
5.949
6.096
5.834
5.935
5.99
5.456
5.727
5.57
5.965
6.142
5.813
5.924
5.599
5.813
6.047
6.495
6.674
5.713
age
G
65.2
78.9
61.1
45.8
54.2
58.7
66.6
96.1
100
85.9
94.3
82.9
39
61.8
84.5
56.5
29.3
81.7
36.6
69.5
98.1
89.2
91.7
100
94.1
85.7
90.3
88.8
94.4
87.3
94.1
dis
H
4.09
4.9671
4.9671
6.0622
6.0622
6.0622
5.5605
5.9505
6.0821
6.5921
6.3467
6.2267
5.4509
4.7075
4.4619
4.4986
4.4986
4.2579
3.7965
3.7965
3.7979
4.0123
3.9769
4.0952
4.3996
4.4546
4.682
4.4534
4.4547
4.239
4.233
rad
|
1
2
2
3
3
3
5
5
5
5
5
5
5
4
4
4
4
4
4
4
4
4
4
4
4
tax
4
4
4
4
4
4
296
242
242
222
222
222
311
311
311
311
311
311
311
307
307
307
307
307
307
307
307
307
307
307
307
307
307
307
307
307
307
K
ptratio
15.3
17.8
17.8
18.7
18.7
18.7
15.2
15.2
15.2
15.2
15.2
15.2
15.2
21
21
21
21
21
21
21
21
21
21
21
21
21
21
21
21
21
21
b
L
396.9
396.9
392.83
394.63
396.9
394.12
395.6
396.9
386.63
386.71
392.52
396.9
390.5
396.9
380.02
395.62
386.85
386.75
288.99
390.95
376.57
392.53
396.9
394.54
394.33
303.42
376.88
306.38
387.94
380.23
360.17
Istat
M
4.98
9.14
4.03
2.94
5.33
5.21
12.43
19.15
29.93
17.1
20.45
13.27
15.71
8.26
10.26
8.47
6.58
14.67
11.69
11.28
21.02
13.83
18.72
19.88
16.3
16.51
14.81
17.28
12.8
11.98
22.6
N
medv
24
21.6
34.7
33.4
36.2
28.7
22.9
27.1
16.5
18.9
15
18.9
21.7
20.4
18.2
19.9
23.1
17.5
20.2
18.2
13.6
19.6
15.2
14.5
15.6
13.9
16.6
14.8
18.4
21
12.7
B
O
a
I

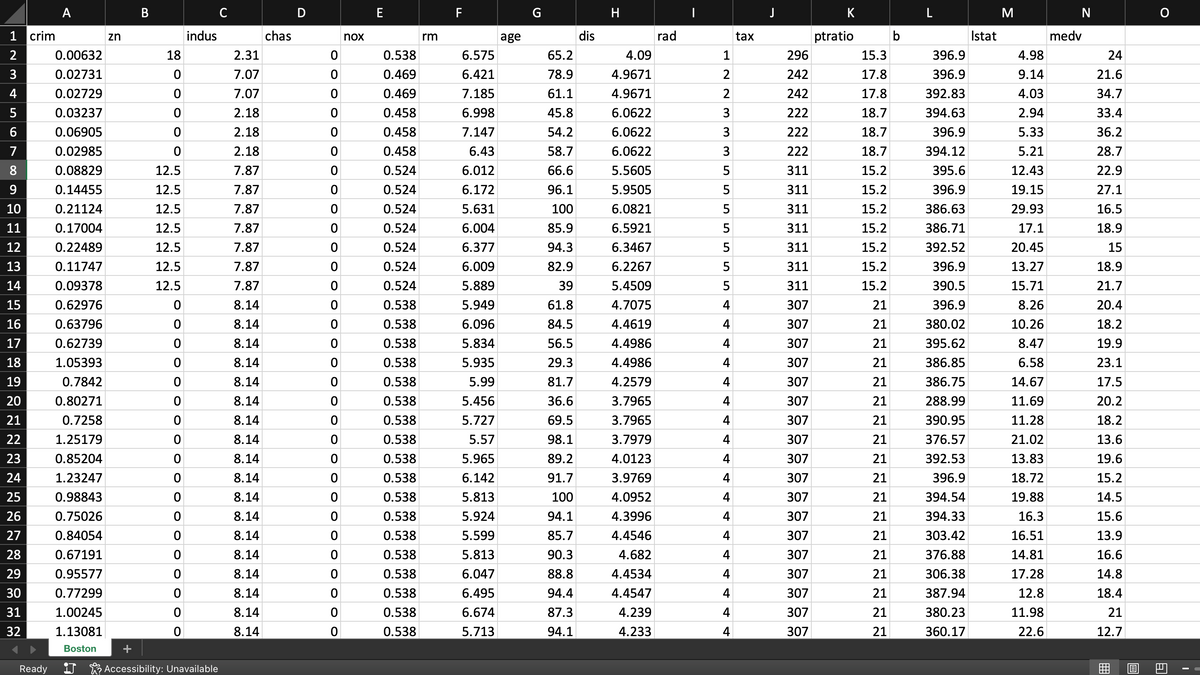
Transcribed Image Text:You are working as a data scientists and you have received data on house prices in the Boston region.
The data set contains the following variables:
• crim: per capita crime rate by town
• zn: proportion of residential land zoned for lots over 25,000 sq.ft.
• indus: proportion of non-retail business acres per town
• chas: Charles River dummy variable (= 1 if tract bounds river; 0 otherwise)
• nox: nitric oxides concentration
• rm: average number of rooms per dwelling
•age: proportion of owner-occupied units built prior to 1940
• dis: weighted distances to five Boston employment centers
• rad: index of accessibility to radial highways
• tax: full-value property-tax rate per $10,000
ptratio: pupil-teacher ratio by town
• b: 1000(Bk - 0.63)² where Bk is the proportion of blacks by town
Istat: % lower status of the population
• medv: Median value of owner-occupied homes in $1000s
Given this information:
1. Download the dataset boston.csv and open it as a PANDAS dataframe.
2. Using 'medv' as the response variable and per capita crime rate by town, proportion of owner-occupied units built prior to 1940, and nitric oxides
concentration as predictors, fit a linear model (OLS), and a k-nearest neigherbour model (using the 5 nearest neighbour). Which one has better prediction
properties using k-fold cross validation (k=5)? Explain why.
3. Fit a model to predict the house prices using crim, zn, indus, chas,nox,rm, age, dis, rad, tax,ptratio, b, and Istat, using OLS, Ridge, and Lasso. Show the
coefficients. Use lambda equal .1 to both Ridge and Lasso. What variable(s) can be eliminated from the analysis based on the Lasso results?
Expert Solution
This question has been solved!
Explore an expertly crafted, step-by-step solution for a thorough understanding of key concepts.

Step by stepSolved in 6 steps with 2 images

Knowledge Booster

Similar questions
- Look up student MAJOR and ROOM information based on the student NAME. Enter formula into B2. 1 NAME MAJOR ROOM 2 58 3 4 NAME MAJOR ROOM 5 $1 CIS DBH 6 S2 7 3 A/F DBH A/F DBH 8 $4 мом SCI 9 S5 мом DBH 10 56 CIS SCI 11 S7 CIS DBH 12 S8 A/F 13 S9 мом 14 S10 CIS Size Color Price Item T. 15 Size L T M 16 Color R. 17 Price 28 H. 29 30 XL R. 18arrow_forward4. Find all instructors in Finance department who have taught some course in 2008. 5. Find all students from Physics department who took course 'CS-319|* .arrow_forwardhelp plz i will rate you discrete structurearrow_forward
- Use a data set of property value from 2007 - 2019. The data contains sale price for houses and units with 1, 2, 3, 4, and 5 bedroom. The data is: date of sale; price in dollars; property type (unit or house); number of bedrooms Using R, calculate and show the mean price of the house properties and unit properties. ```{r} ```arrow_forwardThe InstantRide Driver Relationship team wants to learn how many travels each driver has done in the month of October. You need to send them the DRIVER_ID, and two calculated columns: DAY and RIDES. The DAY column is calculated using the DAY() function with the TRAVEL_START_TIME as the argument. The RIDES column is calculated by using the COUNT() function to determine the number of rides given for each day. Filter the results with the MONTH function.arrow_forwardF A E a. b. C. B d. C 8 00 7- 6 5 What do the letters in the box plot above represent? 3- 2 1- D A = Mean, B = Upper Mean Quartile, C = Lower Mean Quartile, D = Inter Quartile Range, E = Minimum, and F = Outliers A = Mean, B = Third Quartile, C = First Quartile, D = Inter Quartile Range, E = Minimum, and F = Outliers A = Median, B = Third Quartile, C = First Quartile, D = Inter Quartile Range, E = Minimum, and F = Outliers A = Median, B = Third Quartile, C = Mean. D = Inter Quartile Range. E =arrow_forward
arrow_back_ios
arrow_forward_ios