Related questions
Question
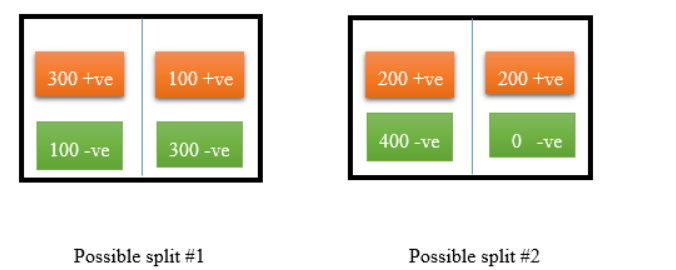
There is a dataset of 800 patients tested for Chronic Kidney Disease (CKD). The dataset has 400 patients tested positive for CKD and 400 tested negative for CKD (400 + ve; 400 - ve).
Now, suppose you have two possible splits based on a decision tree classifier.
Possible split #1:
(300 + ve; 100 - ve) and (100 + ve; 300 - ve)
Possible split #2:
(200 + ve; 400 - ve) and (200 + ve; 0 - ve).
1. Calculate the Misclassification index for split #1 and split #2?
2. Calculate the Gini index for split #1 and split #2?
3. Which one of the two splitting methods is better and why?

Transcribed Image Text:300 +ve
100 -ve
100 +ve
300 -ve
Possible split #1
200 +ve
400-ve
200 +ve
0 -ve
Possible split #2
Expert Solution
This question has been solved!
Explore an expertly crafted, step-by-step solution for a thorough understanding of key concepts.

Step by stepSolved in 3 steps

Knowledge Booster

Similar questions
- A pure subset in a decision tree is 1 A subset with similar values of target variable A subset with 50:50 values of target variable A subset with a mix of values of target variable A subset with one predictionarrow_forwardGiven is a Decision Tree Diagram. The Payoffs 1-14 are given in the table below. Answer questions a, b, and c. Payoff 1 2 3 4 5 6 7 8 9 10 11 12 13 14 $ 6 -3 5 5 8 5 5 -1 5 4 5 2 7 5 a) The value at node 4 is ( )b) The value at node 8 is ( ) (in 1 decimal place) c) The best course of action or decision is to select alternative ( )arrow_forwardPls solve this Question By hand use the ID3 Algorithm.arrow_forward
arrow_back_ios
arrow_forward_ios